Computer Forum
Computer Forum
Hardware Testbericht
Monitore
Hardware
Testbericht
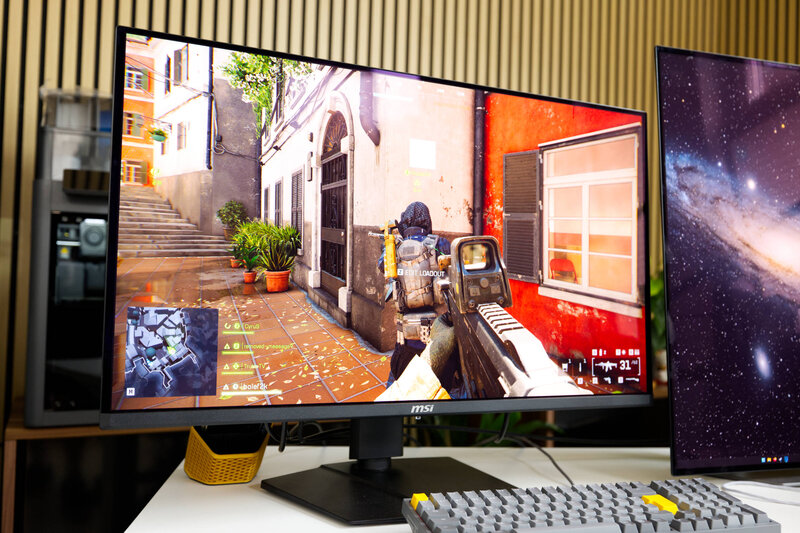
MSI MAG 321UPDE 31,5"-QD-OLED-Monitor im Test
MSI hat bereits einige Monitore auf den Markt gebracht, die sowohl für die Arbeit als auch für Gaming ausgelegt sind. Mit dem MAG 321UPDE schauen wir uns einen Monitor von MSI an, der mit 31,5"-Diagonale, 165-Hz-Bildwiederholrate und QD-OLED-Panel vor allem Gamerherzen höher schlagen lässt. Wie gut sich der Monitor mit einem Marktpreis von 599 € schlägt, klären wir in unserem Test.