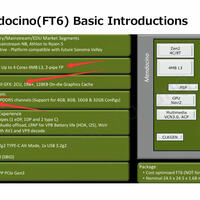
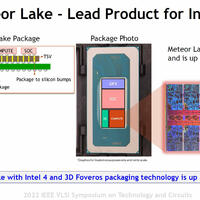
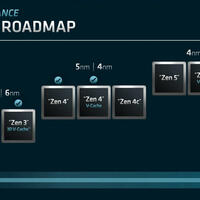
Computer Forum
Computer Forum
Monitore
News
Hardware
ASUS zeigt neue ROG Strix und TUF Gaming-Monitore mit 4K-Fast-IPS und mit Dual-Mode
ASUS hat die Verfügbarkeit der drei neuen Gaming-Monitoren bekantn gegeben, darunter der ROG Strix XG27UCG Gen2, der ROG Strix XG27UCS Gen2 und der TUF Gaming VG27UQEL5A. Diese Displays wurden entwickelt, um eine hohe Bildschärfe bei hoher Auflösung mit den für Wettkampfspiele erforderlichen hohen Bildwiederholraten in Einklang zu bringen.