 Computer Forum
Computer Forum
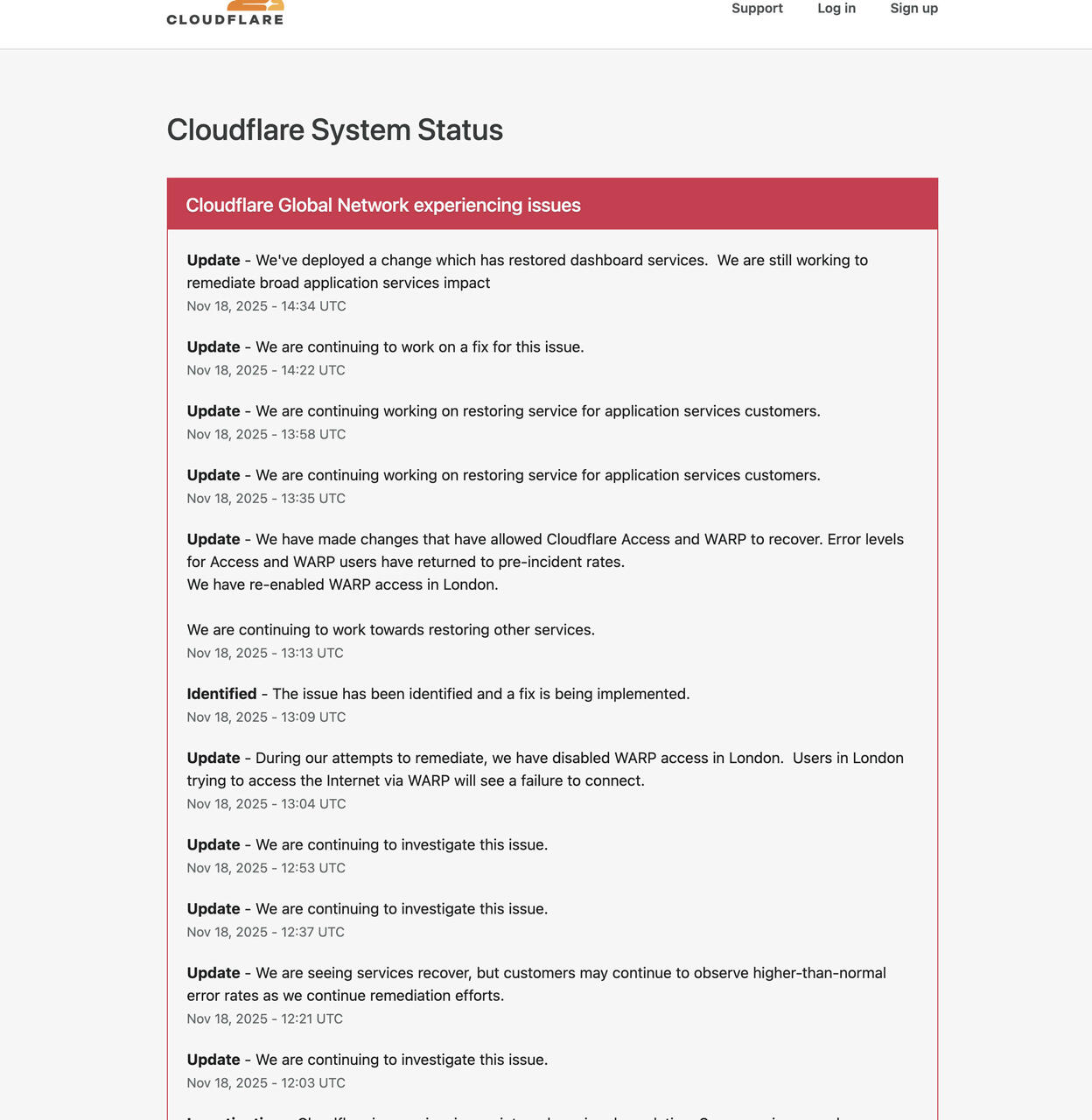 Cloudflare Ausfall (Bild © Cloudflare)
Cloudflare Ausfall (Bild © Cloudflare)
Was ist passiert
Cloudflare hat um 12:48 Uhr MEZ interne Dienstbeeinträchtigungen gemeldet, die sich auf Kundenanwendungen weltweit auswirkten. Besucher sahen Fehlermeldungen oder wurden durch Zwischenanzeigen wie „Allow challenges.cloudflare.com to continue” (challenges.cloudflare.com weiterhin zulassen) blockiert, was darauf hindeutete, dass Anfragen am Edge nicht wie erwartet ausgeführt wurden.
Problem bei Cloudflare viele Websites
Cloudflare betreibt ein globales Anycast-Edge-Netzwerk, das zwischen Endnutzern und Ursprungsservern sitzt. Es überprüft Anfragen auf böswillige Aktivitäten, wendet Leistungsfunktionen (Caching, TLS-Terminierung, Bildoptimierung) an und leitet dann sauberen Datenverkehr vom nächstgelegenen Rechenzentrum weiter. Wenn Teile dieser Struktur nicht richtig funktionieren, können Millionen von Domains, die davon abhängig sind, gleichzeitig beeinträchtigt werden oder ausfallen.
Die meisten Ausfälle wurden als HTTP 500 angezeigt, ein serverseitiger Fehler. Da der Fehler innerhalb der Infrastruktur von Cloudflare lag, gab es keine sinnvolle Abhilfe für Endnutzer außer einem erneuten Versuch. Sowohl Administratoren als auch Nutzer meldeten, dass entweder die 500-Seite oder die Eingabeaufforderung challenges.cloudflare.com nicht abgeschlossen werden konnte.
Zeitachse des Vorfalls
- 18.November 2025 – 14:34 UTC - Update – Wir haben eine Änderung gemacht, die die Dashboard-Dienste wieder zum Laufen gebracht hat. Wir arbeiten immer noch daran, die Auswirkungen auf die Anwendungsdienste zu beheben.
-
- November 2025 – 14:22 UTC - Update – Wir arbeiten weiter an einer Lösung für dieses Problem.
- 18.November 2025 – 13:58 UTC - Update – Wir arbeiten weiter daran, den Dienst für Kunden von Anwendungsdiensten wiederherzustellen.
- 18.November 2025 – 13:35 UTC - Update – Wir arbeiten weiter daran, den Service für Kunden von Anwendungsdiensten wiederherzustellen.
- 18.November 2025 – 13:13 UTC - - Update – Wir haben Änderungen vorgenommen, die die Wiederherstellung von Cloudflare Access und WARP ermöglicht haben. Die Fehlerraten für Access- und WARP-Benutzer sind wieder auf das Niveau vor dem Vorfall zurückgegangen.
- 18.November 2025 – 13:13 UTC - Wir arbeiten weiter daran, andere Dienste wiederherzustellen.
- 18 November 2025 – 13:09 UTC - Identifiziert – Das Problem wurde identifiziert und eine Lösung wird gerade umgesetzt.
- 18.November 2025 – 13:04 UTC - Update – Während wir versuchen, das Problem zu beheben, haben wir den WARP-Zugang in London deaktiviert. Nutzer in London, die versuchen, über WARP auf das Internet zuzugreifen, werden eine Verbindungsfehlermeldung bekommen.
- 18.November 2025 – 12:53 UTC - Update – Wir untersuchen das Problem weiter.
- 18.November 2025 – 12:37 UTC - Update – Wir checken das Problem weiter.
- 18.November 2025 – 12:21 UTC - Update – Die Dienste laufen langsam wieder, aber während wir weiter daran arbeiten, kann es sein, dass die Fehlerrate höher als normal ist.
- 18.November 2025 – 12:03 UTC - Update – Wir checken das Problem weiter.
- 18.November 2025 – 11:48 UTC -Untersuchung – Bei Cloudflare gibt's gerade Probleme mit dem internen Service. Einige Dienste können zeitweise beeinträchtigt sein. Wir arbeiten daran, den Service wiederherzustellen. Wir geben Bescheid, sobald wir das Problem behoben haben. Weitere Updates folgen in Kürze.
Betroffene Dienste
Jede Website oder API, die bei Cloudflare endet, könnte betroffen sein. Dazu gehören LLM-Frontends (z. B. ChatGPT), soziale Plattformen Twitter/X, Messaging-Dienste (WhatsApp), Tools für Zusammenarbeit und Kreativität sowie verschiedene Publisher-Websites. Der Schweregrad variierte je nach Region und Produkt, abhängig davon, welche Rechenzentren und Dienste eine bestimmte Domain nutzt.
Für diese Art von Vorfall gibt's keine Lösung auf Kundenseite. Die Empfehlung von Cloudflare lautet im Grunde, es später nochmal zu versuchen, während sich das Edge-Netzwerk wieder normalisiert und die Caches neu gefüllt werden. Website-Betreiber können den Zustand ihrer eigenen Origin-Server überwachen, aber wenn der Datenverkehr aufgrund eines Upstream-Edge-Fehlers nicht bis zur Origin gelangt, bleibt die Abhilfe auf Seiten des Anbieters.
