 Computer Forum
Computer Forum
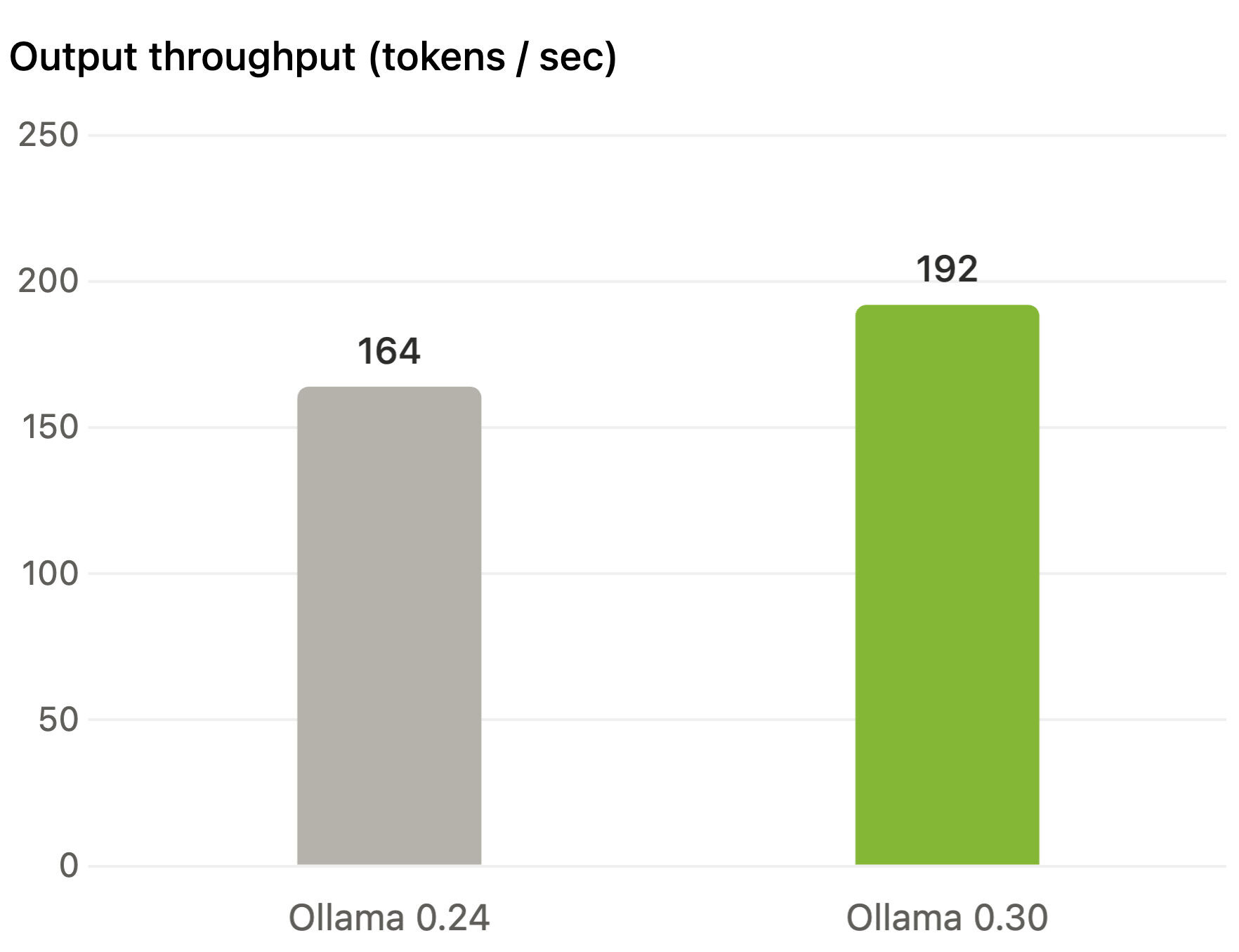 Ollama 0 30 verbessert die GPU Leistung (Bild © Ollama)
Ollama 0 30 verbessert die GPU Leistung (Bild © Ollama)
Hardwarebeschleunigung und Durchsatz
Das Update bringt messbare Leistungssteigerungen für NVIDIA-Nutzer, wobei der Durchsatz um bis zu 20 % steigt. Diese Verbesserungen sind das Ergebnis von Optimierungen, die in Zusammenarbeit mit den Teams von NVIDIA und llama.cpp entwickelt wurden. Tests auf einer NVIDIA RTX 5090 unter Verwendung des Gemma 4 26B-Modells mit Q4_K_M-Quantisierung bestätigen diese Effizienzsteigerungen. Über NVIDIA hinaus aktiviert Ollama 0.30 standardmäßig Vulkan. Diese Änderung erweitert die GPU-Beschleunigung auf eine breitere Palette von Hardware und kommt insbesondere Nutzern mit AMD- und Intel-Geräten zugute. Durch die Nutzung von Vulkan können diese Nutzer sofort auf die GPU-Leistung zugreifen, ohne zusätzliche herstellerspezifische Bibliotheken installieren zu müssen.
Erweiterte Modellkompatibilität
Ollama 0.30 erhöht die Kompatibilität innerhalb des GGUF-Ökosystems. Dies ermöglicht die sofortige Bereitstellung mehrerer neuer Modellfamilien, darunter Prism und LFM, sowie verschiedener von Unsloth veröffentlichter, feinabgestimmter Modelle. Das Update vereinfacht zudem die Ausführung von GGUF-Modellen, die von Hugging Face stammen. Um diese Modelle zu implementieren, können Nutzer die GGUF-Datei herunterladen und mithilfe des Befehls „FROM“ eine Modeldatei erstellen, die auf den spezifischen Dateipfad verweist. Sobald die Modeldatei konfiguriert ist, kann das Modell über Standardbefehle von Ollama erstellt und ausgeführt werden.
Integration von Tool-Aufrufen und Codierungsassistenten
Die Funktionalität für den Tool-Aufruf wird nun in Ollama vollständig unterstützt, sofern das zugrunde liegende Modell über die entsprechenden Fähigkeiten verfügt. Dies ermöglicht es der Software, direkt mit verschiedenen Coding-Agenten und persönlichen Assistenten zu kommunizieren. Zu den unterstützten Integrationen gehören Claude Code, Hermes Agent und OpenClaw, die über einen einzigen Befehl gestartet werden können, der das ausgewählte Modell angibt. Um sicherzustellen, dass ein Modell mit diesen Agenten kompatibel ist, können Benutzer die Tool-Aufruf-Fähigkeiten mit dem Befehl ollama show überprüfen.
Diese Entwicklungen wurden durch technische Kooperationen mit den Betreuern von llama.cpp und Hardware-Partnern wie Intel, Qualcomm, AMD und NVIDIA ermöglicht, wobei der Schwerpunkt auf der Optimierung des GGML-Ökosystems auf verschiedenen Plattformen lag.
