 Computer Forum
Computer Forum
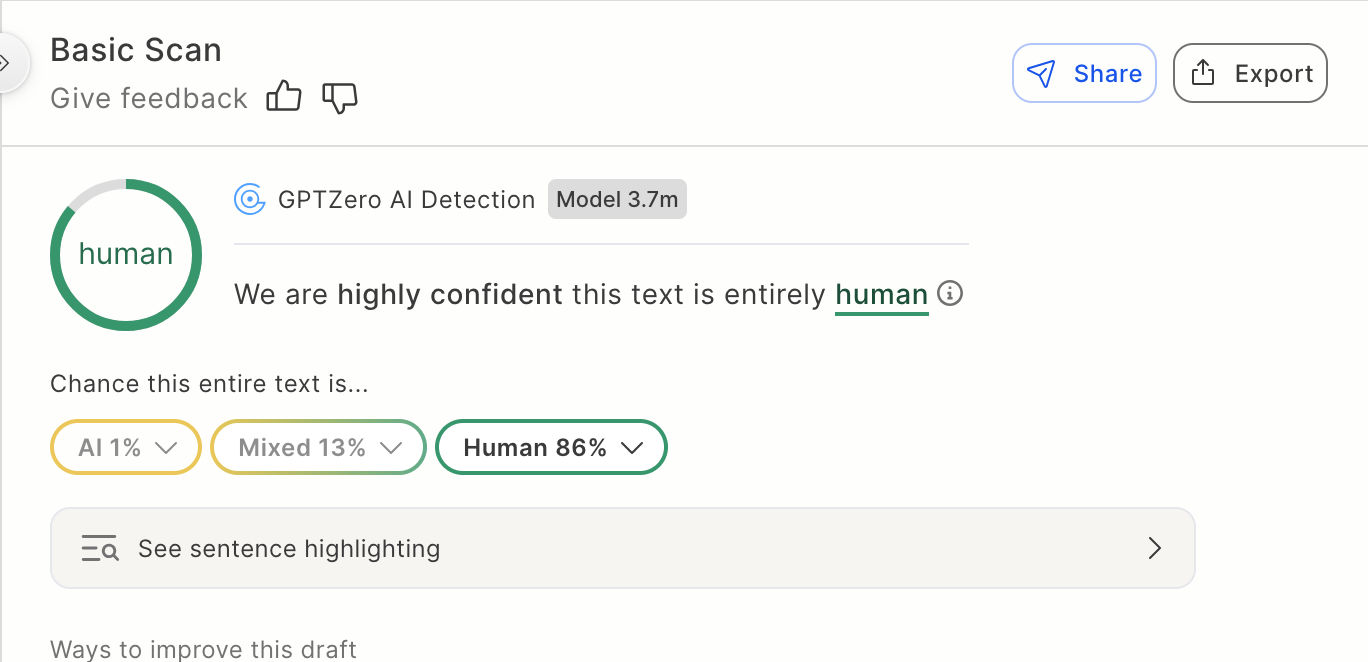 Erkennung von KI Inhalten (Bild © PCMasters.de)
Erkennung von KI Inhalten (Bild © PCMasters.de)
Erkennung von KI-Inhalten
Die technische Grundlage dieser Scanner beruht auf statistischer Analyse, insbesondere auf Perplexität und Burstiness. Perplexität bewertet, wie vorhersehbar ein Text ist; da große Sprachmodelle darauf ausgelegt sind, das wahrscheinlichste nächste Wort auszuwählen, weist ihre Ausgabe in der Regel eine geringe Perplexität auf. Deshalb hört man oft, dass LLMs nur die besseren Auto-Textvervollständiger sind. Burstiness bezieht sich auf die Varianz in der Satzstruktur und -länge. Menschliche Texte sind von Natur aus unregelmäßig und wechseln zwischen kurzen und komplexen Sätzen, wohingegen künstliche Intelligenz dazu neigt, einen gleichmäßigen, rhythmischen Rhythmus beizubehalten. High-End-Detektoren ergänzen diese Metriken durch neuronale Netze, die auf die Erkennung von Mustern in tiefen Schichten trainiert sind.
 Kostenlose KI Detektoren (Bild © PCMasters.de)
Kostenlose KI Detektoren (Bild © PCMasters.de)
Der Mensch im Text
Trotz dieser technischen Schichten sind die stilistischen Marker, die zur Kennzeichnung von KI verwendet werden, oft mehrdeutig. Scanner suchen nach einem Mangel an individueller Perspektive, einem übermäßig formalen Ton und einer Tendenz zu parallelen Satzstrukturen. Im Englischen sind bestimmte Schlüsselwörter zu Markern für KI geworden, aber in anderen Sprachen ist dies weniger effektiv. So ist die Erkennungsgenauigkeit für deutsche Texte deutlich geringer, da weniger Trainingsdaten zur Verfügung stehen und die sprachliche Grammatik komplizierter ist.
Der kritischste Punkt ist nach wie vor die Fehlerquote. Untersuchungen zeigen, dass selbst die effektivsten Scanner mit einer Genauigkeit von 70 bis 80 Prozent arbeiten. Das bedeutet, dass etwa einer von vier Texten falsch klassifiziert wird. Besonders besorgniserregend sind falsch positive Ergebnisse, bei denen ein von Menschen geschriebener Text als KI gekennzeichnet wird. Die Daten zeigen eine systematische Verzerrung, bei der Nicht-Muttersprachler häufiger als künstliche Intelligenz identifiziert werden, wahrscheinlich, weil ihre Texte eher starren oder vorhersehbaren Mustern folgen.
Kostenlose KI Text Detektoren
Für Unternehmen und Verlage verändern diese Ungenauigkeiten den Nutzen von Erkennungsinstrumenten. Dazu machen Menschen auch Fehler und vertippen sich. Was die Suchmaschinenoptimierung betrifft, so herrscht derzeit Konsens darüber, dass Plattformen wie Google dem Wert und der Qualität der dem Nutzer zur Verfügung gestellten Informationen Vorrang einräumen und nicht der Frage, ob der Inhalt mit Hilfe von KI erstellt wurde. Folglich ist es oft weniger produktiv, sich auf die Herkunft eines Textes zu konzentrieren als auf seinen redaktionellen Inhalt.
In professionellen Umgebungen, z. B. bei der Einstellung von Personal oder der Überprüfung von Gastbeiträgen, kann das alleinige Vertrauen auf KI-Scanner zu falschen Entscheidungen führen. Da einfache Paraphrasierungstools oft die Erkennungsfunktionen umgehen können und von Menschen bearbeitete KI-Texte fast unmöglich zu unterscheiden sind, dienen diese Tools eher als allgemeine Orientierungshilfe denn als endgültiger Nachweis der Urheberschaft. Der Trend in der Branche geht in Richtung Qualitätssicherung, bei der die Frage im Vordergrund steht, ob ein Text unabhängig von seiner Quelle gut recherchiert und nützlich ist.
