 Computer Forum
Computer Forum
 NVIDIA und Langflow (Bild © NVIDIA und Langflow)
NVIDIA und Langflow (Bild © NVIDIA und Langflow)
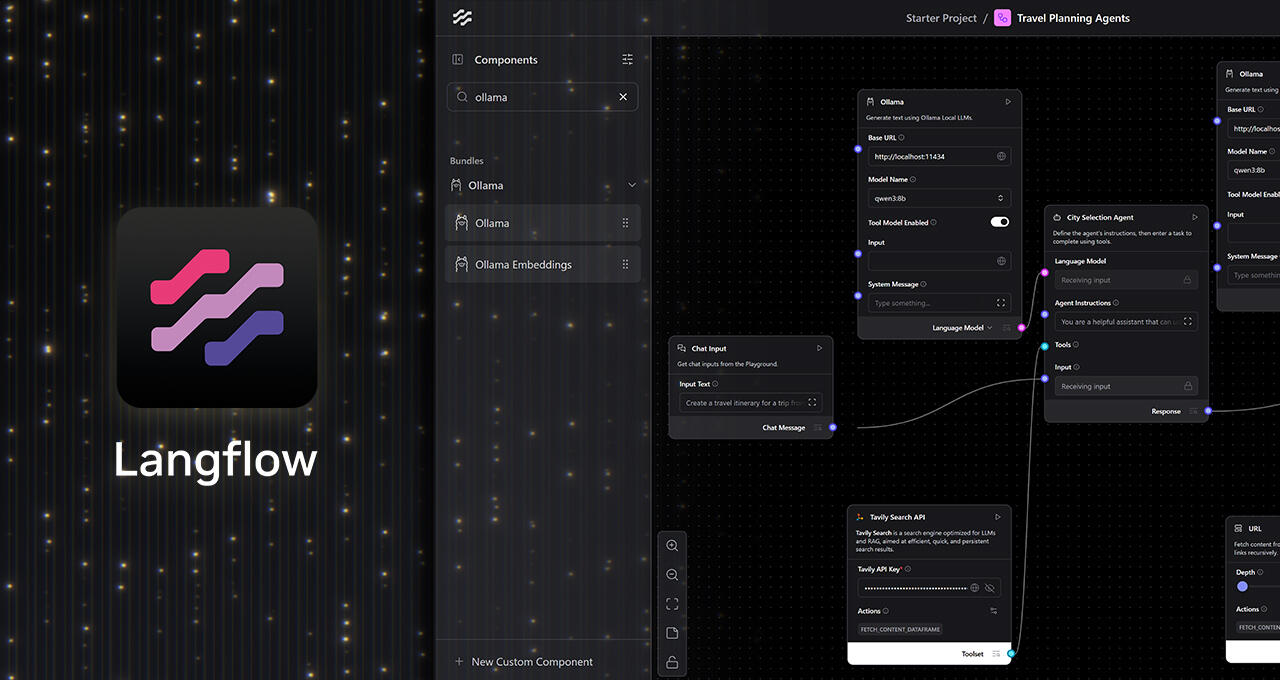
Lokale Agenten, visuell erstellt
Mit den Drag-and-Drop-Knoten von Langflow können Nutzer und Profis Agentenpipelines ohne Skripterstellung zusammenstellen: LLMs, Werkzeuge, Speicher, Controller. Mit dem Ollama-Knoten können dieselben Vorlagen, die standardmäßig für Cloud-Endpunkte verwendet werden, in wenigen Minuten auf lokale Inferenz auf RTX umgestellt werden:
-
- Installiere Langflow (Windows-Desktop).
-
- Installiere Ollama und starte es, dann ziehe ein Modell (z.B. Llama 3.1 8B, Qwen3 4B) für einen ersten Workflow.
-
- Öffne einen Langflow-Starter (Reisebüro, Einkaufsassistent, etc.).
-
- Ersetze den LLM-Endpunkt durch den Ollama-Knoten und verbinde die Modelleingabe des Agenten mit der Ollama-Ausgabe.
-
- Erweitere sie nach Bedarf mit Systembefehlen, lokaler Dateisuche, strukturierten Ausgaben oder eigenen Tools.
Durch die lokale Ausführung wird der Datenschutz gewahrt, es fallen keine Token-Kosten an, die Latenz/Durchsatzrate wird durch die RTX-Beschleunigung verbessert (nützlich bei langen Kontextfenstern) und es funktioniert offline- eine praktische Kombination für persönliche Wissensassistenten und Desktop-Automatisierungen.
 Langflow Agenten (Bild © NVIDIA und Langflow)
Langflow Agenten (Bild © NVIDIA und Langflow)
RTX Remix erhält MCP-Unterstützung für agentengesteuertes Modding
RTX Remix- das Open-Source-Toolkit für Raytracing-Remaster - unterstützt jetzt das Model Context Protocol (MCP) über Langflow-Knoten. MCP bietet Agenten eine standardisierte Schnittstelle zu Dokumentation und Funktionen. Die Remix Langflow-Vorlage enthält:
- RAG over RTX Remix-Dokumentation für kontextbezogene Fragen und Antworten,
- Echtzeit-Doku-Zugriff für Disambiguierung und Anleitung,
- MCP-Aktionen, die Remix-Funktionen ausführen können - Ersetzen von Assets, Bearbeiten von Metadaten, automatisierte Mod-Schritte.
Agenten können entscheiden, wann sie mit einer Anleitung antworten oder direkt handeln. Ein typischer Ablauf: Analyse einer Benutzeranfrage („Ersetze eine niedrig aufgelöste Textur“), Überprüfung des Projekts, Auswahl eines geeigneten Assets und Aktualisierung von Remix über MCP - so werden die manuellen Schritte für Modder minimiert.
 Langflow Workflow (Bild © NVIDIA und Langflow)
Langflow Workflow (Bild © NVIDIA und Langflow)
Project G-Assist wird ein Baustein in Langflow
Project G-Assist, NVIDIAs experimenteller On-Device-Assistent für GeForce RTX-PCs, stellt Telemetrie- und Kontroll-PCs, CPU/GPU-Temperaturen, Auslastung und Lüfterkurven als Komponente in Langflow zur Verfügung. Workflows können den Systemstatus abfragen („GPU-Temperaturen abfragen“) oder Einstellungen ändern („Lüfterdrehzahlen einstellen“), indem sie natürliche Sprache verwenden und Antworten und Aktionen durch breitere Agentenketten leiten. Eine Plug-in-Architektur ermöglicht neue Befehle, und Community-Plug-ins können direkt in Langflow aufgerufen werden.
Langflow für NeMo Microservices
Über die Desktop-Agenten hinaus bietet Langflow eine Schnittstelle zu den NVIDIA NeMo-Microservices, die es Teams ermöglicht, Pipelines in On-Prem- oder Cloud-Kubernetes-Umgebungen zu entwerfen und zu implementieren und dann mit denselben visuellen Mustern zu iterieren, die sie lokal verwenden.
Lokale RTX-Workflows skalieren
Black Mixture, ein Studio für Motion Design und Produktion, hat einen großen Teil seiner Pipeline auf lokale, GPU-beschleunigte KI auf einer GeForce RTX 4090 umgestellt. In ComfyUI mischt das Team Modelle wie FLUX.1-dev und FLUX.1 Kontext, um Video- und Bildinhalte schnell zu iterieren:
- Typische 1024×1024-Generationen werden in ~2-3 Sekunden auf der RTX 4090 in Standard-T2I-Grafiken abgeschlossen - schnell genug, um Hunderte von Variationen pro Sitzung zu bearbeiten.
- FLUX.1 Kontext ermöglicht geführte Bearbeitungen von einem Prompt-Fenster aus (Posen, Kanten, Tiefe) und vermeidet so Multi-ControlNet-Setups. Quantisierte FP8/FP4-Varianten reduzieren den VRAM und beschleunigen die Inferenz, wobei FP8 auf der RTX 40 und FP4 auf der RTX 50 unterstützt wird; TensorRT-Optimierungen verbessern den Durchsatz weiter.
- Stable Diffusion 3.5 unterstützt FP8 auf der RTX 40, wodurch der VRAM um ~40% reduziert wird und die Geschwindigkeit gegenüber FP16-Pfaden in unterstützten Pipelines um den Faktor 2 zunimmt.
Für die Aufnahme und das Finishing nutzt das Studio NVENC in OBS Studio und Premiere Pro, wobei die Codierung auf einer dedizierten GPU-Engine erfolgt, damit CUDA-Kerne für KI-Workloads frei bleiben. Die RTX-beschleunigten KI-Funktionen von Premiere (z. B. Sprachanhebung) und NVENC-Exporte verkürzen die Bearbeitungszeiten. Das Team bereitet einen Kurs für fortgeschrittene generative KI vor, der Workflows auf dem Gerät und RTX-Optimierungen abdeckt.
